-- 授予用户 'john' 在 'employees' 数据库上的 SELECT 和 INSERT 权限 GRANT SELECT, INSERT ON employees.* TO 'john'@'localhost';
-- 授予用户 'john' 在 'employees' 表上的 UPDATE 权限 GRANT UPDATE ON employees.employees TO 'john'@'localhost';
-- 授予用户 'john' 在数据库上的 CREATE 和 DROP 权限 GRANT CREATE, DROP ON *.* TO 'john'@'localhost';
4.2、撤销权限
1 2 3 4 5 6 7 8
-- 撤销用户 'john' 在 'employees' 数据库上的 INSERT 权限 REVOKE INSERT ON employees.* FROM 'john'@'localhost';
-- 撤销用户 'john' 在 'employees' 表上的 UPDATE 权限 REVOKE UPDATE ON employees.employees FROM 'john'@'localhost';
-- 撤销用户 'john' 的 CREATE 权限 REVOKE CREATE ON *.* FROM 'john'@'localhost';
这个简单看看就好,交给DBA去吧。接下来才是重头戏 **DQL **登场了
五、DQL —- 数据查询语言,用来查询数据库中的表记录
🆗我们由浅入深 ,从易到难慢慢来
5.1、基本语法
1 2 3 4 5 6 7
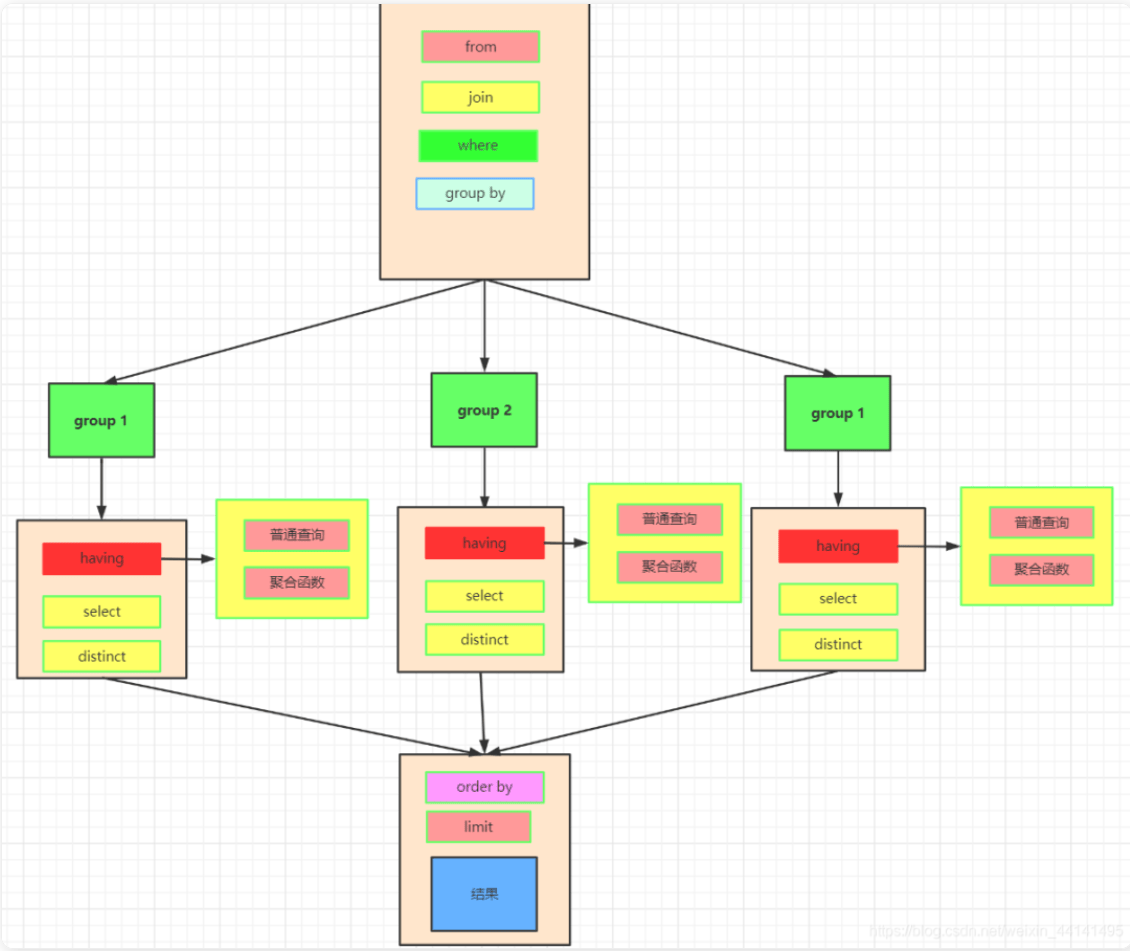
SELECT [DISTINCT] 要查询的字段列表 -- SELECT:指定返回列(必需) FROM table_name -- FROM:指定数据源表(必需) [WHERE 查询条件] -- WHERE:行级过滤条件 [GROUP BY 分组字段列表] -- GROUP BY:分组依据 [HAVING 分组后条件列表] -- HAVING:分组后过滤 [ORDER BY 排序字段列表 [ASC|DESC]] -- ORDER BY:结果排序 [LIMIT 分页参数]; -- LIMIT:结果集限制
5.2、聚合函数
函数
功能
count
统计数量
max
最大值
min
最小值
avg
平均值
sum
求和
使用语法
1 2 3 4 5 6 7 8 9 10
SELECT 聚合函数(字段列表) FROM 表名;
-- 常用聚合函数 SELECT COUNT(*) AS total_orders, -- AS就是起别名 AVG(order_total) AS average_order, MAX(order_date) AS latest_order, MIN(ship_date) AS earliest_shipment, SUM(quantity) AS total_items FROM orders;
5.3、SELECT子句
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- 基础查询 SELECT * FROM employees; -- 查询所有列
-- 指定列查询 SELECT employee_id, first_name, salary FROM employees;
-- 使用表达式 SELECT product_name, unit_price * quantity AS total_price FROM order_details;
-- 常数列 给查询结果都加上一个属性 status ,值是Active SELECT 'Active' AS status, employee_name FROM employees;
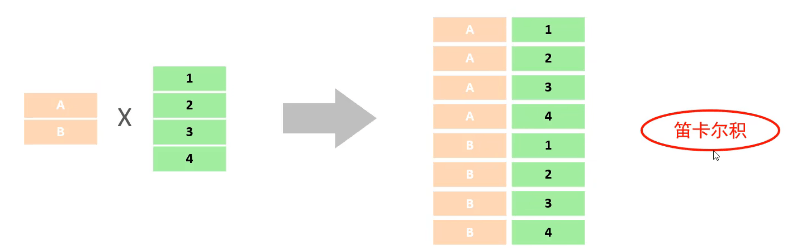
-- T1 SELECT * FROM 员工表 WHERE age IN (20,21,22,23);
-- T2 SELECT * FROM 员工表 WHERE gender = '男' AND (age BETWEEN 20 AND 40) AND name REGEXP '^[^,]{3}$'; SELECT * FROM 员工表 WHERE gender = '男' AND (age BETWEEN 20 AND 40) AND name like '___'; -- T3 SELECT gender, COUNT(*) FROM 员工表 WHERE age < 60 GROUP BY gender;
-- T4 SELECT name,age FROM 员工表 WHERE age <= 35 GROUP BY age ASC,入职时间 DESC;
-- T5 SELECT * FROM 员工表 WHERE gender = '男' AND (age BETWEEN 20 AND 40) ORDER BY age,入职时间 LIMIT 5;
5.10、SQL的书写顺序与执行顺序
执行顺序
SQL 关键字
作用
①
FROM
确定主表,准备数据
②
ON
连接多个表的条件
③
JOIN
执行 INNER JOIN / LEFT JOIN 等
④
WHERE
过滤行数据(提高效率)
⑤
GROUP BY
进行分组
⑥
HAVING
过滤聚合后的数据
⑦
SELECT
选择最终返回的列
⑧
DISTINCT
进行去重
⑨
ORDER BY
对最终结果排序
⑩
LIMIT
限制返回行数
六、一些函数
6.1、聚合函数
AVG(表达式) 返回表达式中所有的平均值。仅用于数字列并自动忽略NULL值。
COUNT(表达式) 返回表达式中非NULL值的数量。可用于数字和字符列。
COUNT(*) 返回表中的行数(包括有NULL值的列)。
MAX(表达式) 返回表达式中的最大值,忽略NULL值。可用于数字、字符和日期时间列。
MIN(表达式) 返回表达式中的最小值,忽略NULL值。可用于数字、字符和日期时间列。
SUM(表达式) 返回表达式中所有的总和,忽略NULL值。仅用于数字列。
6.2、字符串函数
函数
作用描述
CONCAT(S1, S2, …, Sn)
字符串拼接,将 S1、S2、…、Sn 拼接成一个字符串
LOWER(str)
将字符串 str 全部转为小写
UPPER(str)
将字符串 str 全部转为大写
LPAD(str, n, pad)
左填充,用字符串 pad 对 str 的左边进行填充,达到 n 个字符长度
RPAD(str, n, pad)
右填充,用字符串 pad 对 str 的右边进行填充,达到 n 个字符长度
TRIM(str)
去掉字符串头部和尾部的空格
SUBSTRING(str, start, len)
返回从字符串 str 从 start 位置起的 len 个长度的字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14
SELECT CONCAT('Hello', ' ', 'World') AS result; -- 结果:Hello World SELECT LOWER('HELLO WORLD') AS result; -- 结果:hello world SELECT UPPER('hello world') AS result; -- 结果:HELLO WORLD SELECT LPAD('Hello', 10, ' ') AS result; -- 结果:' Hello'(左边填充5个空格) SELECT RPAD('Hello', 10, ' ') AS result; -- 结果:'Hello '(右边填充5个空格) SELECT TRIM(' Hello World ') AS result; -- 结果:'Hello World' SELECT SUBSTRING('Hello World', 7, 5) AS result; -- 结果:'World'
6.3、数值函数
函数
功能描述
CEIL(x)
向上取整,返回大于或等于x的最小整数
FLOOR(x)
向下取整,返回小于或等于x的最大整数
MOD(x, y)
返回x除以y后的余数
RAND()
返回0到1之间的随机数
ROUND(x, y)
对x进行四舍五入,并保留y位小数
1 2 3 4 5 6 7 8 9 10
SELECT CEIL(5.2) AS ceil_value; -- 结果:6 SELECT FLOOR(5.9) AS floor_value; -- 结果:5 SELECT MOD(10, 3) AS mod_value; -- 结果:1 SELECT RAND() AS random_value; -- 结果:0.5678(每次执行都会返回不同的随机值) SELECT ROUND(5.768, 2) AS rounded_value; -- 结果:5.77
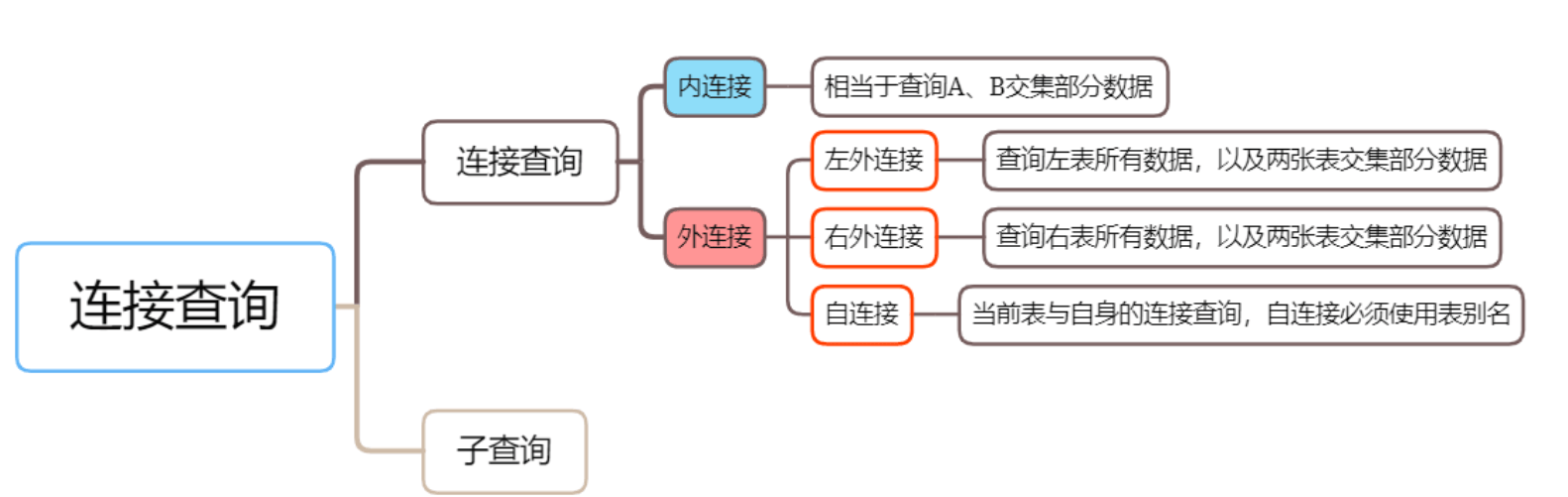
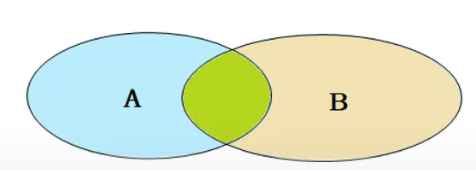
-- T1 SELECT name, age, position, department_id FROM employees; -- T2 SELECT name, age, position, department_id FROM employees WHERE age < 30; -- T3 SELECT department_id, department_name FROM departments WHERE department_id IN (SELECT DISTINCT department_id FROM employees); -- T4 SELECT e.name, e.age, d.department_name FROM employees e LEFT JOIN departments d ON e.department_id = d.department_id WHERE e.age > 40; -- T5 SELECT name, salary, CASE WHEN salary > 10000 THEN 'High' WHEN salary BETWEEN 5000 AND 10000 THEN 'Medium' ELSE 'Low' END AS salary_level FROM employees; -- T6 SELECT e.name, e.age, e.position, e.salary, CASE WHEN e.salary > 10000 THEN 'High' WHEN e.salary BETWEEN 5000 AND 10000 THEN 'Medium' ELSE 'Low' END AS salary_level FROM employees e JOIN departments d ON e.department_id = d.department_id WHERE d.department_name = '研发部';