
Elasticelassearch的学习笔记
一、环境安装
下载连接:官网下载连接
下载自己想要的对应版本,下载后解压,解压完之后到bin目录点击elasticsearch.bat就行了,然后再访问localhost:9200就🆗了。
 看到这个说明你成功了。
看到这个说明你成功了。
二、核心概念
2.1、倒排索引
在正式学习 Elasticsearch 之前,先来弄清楚一个核心概念 —— 倒排索引。
我们日常使用 MySQL 查询数据,其实用的就是一种叫“正向索引”的方式。
所谓正向索引,就是根据某个主键或字段值,直接定位到一条完整的记录。比如我们想查学生 ID 为 2 的成绩,只要在索引中找到这个 ID,就能迅速取出整行数据。这种方式适合用于结构化数据的精确查找。
E 但 Elasticsearch 更多用于 全文检索,例如查询“花生米”出现在哪些文章中。逐行扫描显然效率低下,于是搜索引擎采用了 倒排索引。
倒排索引的原理很简单:它是根据“词”来找“文档”。就像一本字典的反向目录一样,我们通过一个词条,可以立刻知道它在哪些文档中出现过,从而快速定位搜索结果。
用一个例子来说一下吧,某天你得到了一个菜谱,你想做一个红烧茄子,你就沿着目录一行行寻找,欸🤓👆在66页,你翻到66页,找到了红烧茄子的做法,美美吃了一顿。
✅ 这就是正向索引:你通过菜名(key),找到了具体内容(value),是“文档 → 内容”的过程。
你掌握了红烧茄子的做法,连吃三天,美得很!第四天,你看着茄子陷入沉思:“顿顿红烧,腻了腻了… 得换个茄子的花样!可是啊,这菜谱的目录都是一道道菜名,你压根看不出来哪些菜用到了茄子,你总不能对着目录猜这道菜是不是真有茄子吧?心想(坏了啊,茄子这玩意在这本菜谱上可没有索引啊)。
然后你突发恶疾,欸(🤓👆)我一页一页的翻,我就看这些菜的做法中,哪些用到了茄子 ,把那些用到茄子的菜全部找出来。你翻啊翻啊,人都快饿昏了,菜谱还有一大半没翻完,你肚子咕噜咕噜叫马上就要饿昏了。突然你眼前冒霞光,一个自称菜谱仙人的人出现在你面前,他说到:”少年,这里还有一本美味菜谱pro max 看你我有缘,就送给你了,说完就消失了”,菜谱落入那人手中,他翻开目录,发现跟之前的目录大不相同,这本pro max 的菜谱的目录上面写着:
茄子:
- 酸辣茄子(第20页)
- 茄子煲(第40页)
- 红烧茄子(第66页)
- 地三鲜(第88页)
- ……(还有好多)
你眼前一亮,这也太牛了吧! 这个pro max 居然把用到茄子的菜都一一列举在这里了,我再也不用一页一页翻开看材料了,今天就吃地三鲜了“说罢那人便去做做饭吃去了。(
✅ 这就是倒排索引:根据关键词(比如“茄子”)反过来找出所有相关文档(哪些菜用到了茄子),一步到位,效率极高!
看完了找个小故事,你是不是对倒排索引有些概念了呢?下面正式定义一下倒排索引
倒排索引不是“文档 → 包含哪些词”,而是“词 → 出现在哪些文档中”。
在实际应用中,倒排索引通常由以下两个部分组成:
- 词汇表(Term Dictionary)收集所有文档中出现的唯一词项(Term),比如“茄子”、“辣椒”、“鸡肉”等。
这个过程叫做分词(Tokenization)。
倒排列表(Postings List)
对每个词项,记录它在哪些文档中出现,以及相关信息:- 文档 ID 列表(例如:红烧茄子 = Doc3)
- 出现频率(TF):这个词在某篇文档中出现了几次?
- 位置(Position):在文档中第几句话、第几个词?
- 字段信息、权重等:用于更精准的搜索与排序
当你搜索“茄子”时,Elasticsearch 根本不需要一条一条文档地扫,而是立刻查词表,直接拿到所有含有“茄子”的文档 ID,一下子就搞定!
词条(term)把文档按照语义分成词语
一次搜索的过程
| 文档id | 菜名 | 方法 |
|---|---|---|
| 1 | 红烧茄子 | 茄子切块,油锅炸透,淋秘制酱汁… |
| 2 | 鱼香肉丝 | 里脊肉切丝,配木耳笋丝,鱼香汁爆炒… |
| 3 | 地三鲜 | 茄子、土豆、青椒过油,葱蒜爆香… |
| 4 | 宫保鸡丁 | 鸡胸肉切丁,配花生、干辣椒,宫保汁… |
这是一个索引的文档信息,通过分词,我们变成了这样:
| 词条 (term) | 出现的文档id (菜谱) |
|---|---|
| 茄子 | 1, 3 |
| 肉 | 2 |
| 土豆 | 3 |
| 青椒 | 3 |
| 鸡丁 | 4 |
| 花生 | 4 |
搜索“茄子”时:
- 查词汇表,定位到“茄子”。
- 直接读取倒排列表
[1, 3]。 - 返回文档 1 和 3,几毫秒即可完成。
2.2、分词器
这些词条的出现离不开一个工具-分词器。分词器的作用就是:在你创建倒排索引的时候,对你的文档进行 分词处理,然后在用户搜索时,对输入的内容进行分词。在你创建索引的时候,先通过字符过滤器,清洗原始文本,例如移除HTML标签,转换符号,过滤敏感词等等,然后再用分词器,将处理经过字符处理器处理后的文本按照规则将文本切分成独立的词条(Token),词条存储在倒排索引中。你搜索的时候,输入的内容被分词器分割,去倒排索引中查找,然后组成内容返回?
elasticsearch中的文档(一行数据)数据会被序列化为json格式后存储在elasticsearch中
2.3、Mapping映射
在 Elasticsearch 中,**索引 (Index)** 可以类比为关系型数据库(如 MySQL)中的**表 (Table)**。就像表需要有结构定义一样,Elasticsearch 的索引也有其结构约束,这被称为**映射 (Mapping),**映射定义了文档及其字段的类型、特性以及如何存储和索引数据。它告诉 Elasticsearch 如何处理每个字段的值,例如它们是文本、数字、日期,以及它们是否需要被分词、是否可搜索等。
mapping的结构大致如下:
1 | PUT /users |
**type**:字段的数据类型 这是最核心的属性,它决定了字段的存储方式和可执行的操作。Elasticsearch 提供了多种数据类型,常见的包括:
**text**: 用于需要全文搜索的文本数据,如文章内容、产品描述等。text类型的数据在存储时会经过分词器 (Analyzer) 处理,被拆分成一个个独立的词项(token)。这意味着你可以搜索到文本中的部分关键词。**keyword**: 用于不需要分词的精确值,如产品 ID、标签、国家名称、电子邮件地址等。keyword类型的数据会作为一个整体进行索引,通常用于过滤、排序和聚合。
**index**:是否创建倒排索引 此属性决定了字段是否应该被索引。默认值为 true,意味着该字段会被添加到倒排索引中,从而可以被搜索。如果你有一个字段你永远不需要搜索,只想存储它,那么可以将其设置为 false。
**analyzer**:分词器 这个属性只适用于 text 类型的字段。它指定了在索引和搜索时,应使用哪种分词器 (Analyzer) 来处理文本。分词器负责将原始文本分解成独立的词项,并进行标准化处理(如转换为小写、去除停用词等)
**properties**:字段的子字段 当你需要定义一个对象字段,并且这个对象内部还有多个字段时,就会使用 properties。它允许你为一个字段定义其嵌套结构,每个子字段也可以拥有自己的 type 和其他映射属性。 用于对象或嵌套结构(Nested)。
2.4、索引-Index
在 Elasticsearch 中,**索引 (Index)** 是存储文档的地方,可以理解为关系型数据库中的“数据库”本身,或者是一个大的“表”。每个索引都有自己的 **映射 (Mapping)**,定义了其中文档的结构。
Elasticsearch 索引的一个重要特性是:已存在的字段映射不能被修改,但你可以为索引添加新的字段映射。 这意味着一旦一个字段的类型被定义,就不能直接更改,例如将 text 类型改为 keyword 或其分词器设置 如果需要修改现有字段的映射,通常需要重建索引(即创建一个新索引并重新导入数据)
为什么会有这样的限制?
这是因为 Elasticsearch 在内部存储和索引数据时,会根据字段的映射类型进行优化。一旦数据写入,底层的倒排索引结构就已经确定。更改现有字段的映射,将导致已存储的数据与新的映射不兼容,从而引发数据混乱和搜索错误。
那么,如果我必须修改现有字段的映射怎么办?
唯一的解决方案通常是重建索引 (Reindex)
2.4.1、增加索引
1 | PUT /users |
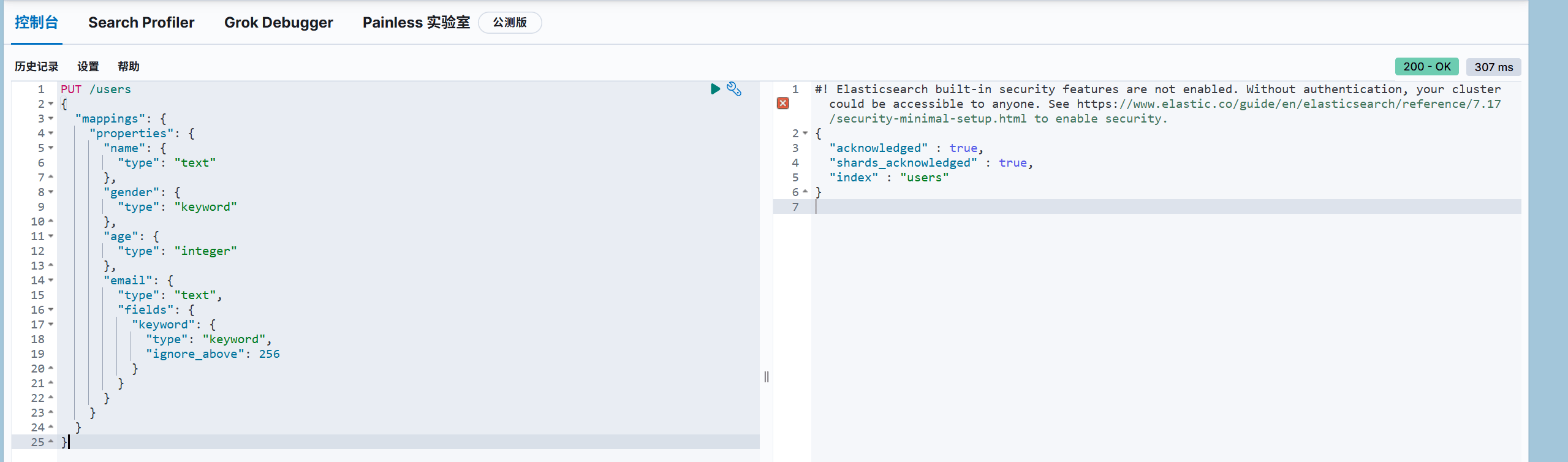
2.4.2、查找索引
1 | GET /索引名称 |
2.4.3、删除索引
1 | DELETE /索引名称 |
2.4.4、添加索引字段
1 | PUT /索引名/_mapping |
三、基础操作:Document CRUD
在 Elasticsearch 中,**文档(Document)是存储的基本数据单元**,相当于 MySQL 表中的一行数据。每个文档都会被自动分配一个 `_id`(可以手动指定),并存储在某个索引(Index)中
新增文档(POST)
1 | POST /索引名称/_doc/文档id |

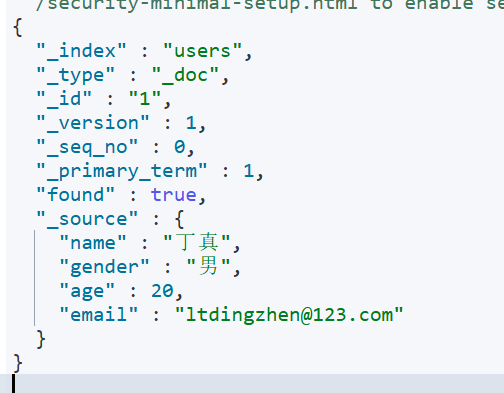
也可以不加id,不加id就会给你一个随机的唯一的id。
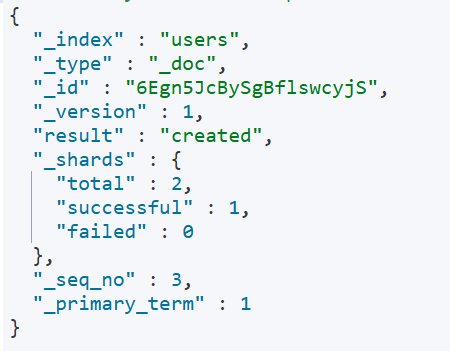
查询文档请求(GET)
1 | GET /索引名称/_doc/id |
删除文档(DELETE)
1 | DELETE /索引名称/_doc/id |
修改文档 (Update)
文档的修改有两种主要方式:全量修改和局部修改
\1. 全量修改 (Full Update / Replace)
全量修改本质上是先删除旧文档,再创建一个同 ID 的新文档。这意味着你必须提供文档的所有字段,如果某些字段在新请求中缺失,它们将从文档中被移除
全量修改
1 | PUT /<索引名称>/_doc/<文档ID> |
简单示例
1 | PUT /users/_doc/1 |
当文档引入新字段时 ES 如何处理?
如果 ID 为 1 的文档原来有 city 字段,执行此操作后,city 字段将被移除。 因为是全量修改,直接把之前的删了,在重新创建一个。
那么问题来了: 如果mapping里面没用address呢?只有city。会怎么样?????
mapping动态映射闪亮登场
在 Elasticsearch 中,如果你在 `PUT` 请求(全量修改)或 `POST` 请求(新增)中提供了一个在当前 **Mapping** 里没有定义的新字段(比如你的 `address` 字段),Elasticsearch 通常会根据这个新字段的数据类型,**自动为你创建新的映射**。这就是 **动态映射 (Dynamic Mapping)**
如何控制动态映射?
你可以通过在索引的映射设置中配置 **dynamic** 属性来控制动态映射的行为:
**"dynamic": "true"**(默认): 自动添加新字段。**"dynamic": "false"**: 忽略新字段,不会将其添加到索引中,也不会抛出错误。**"dynamic": "strict"**: 如果出现未定义的字段,会抛出错误并拒绝文档的索引。
局部修改 (Partial Update)
1 | POST /{索引库名}/_update/文档id |
批量处理 (_bulk API)
每个操作由两行组成(指令行 + 数据行),必须以换行符结尾
_bulk API 允许你在一个请求中执行多个 CRUD 操作(index、create、update、delete),从而显著提高效率。这减少了网络往返次数,对于大规模数据操作非常有用
请求体由一系列 JSON 行组成,每两行代表一个操作:第一行是**元数据行**(定义操作类型、索引、ID 等),第二行是**文档行**(如果是 `index`、`create` 或 `update` 操作)
批处理采用POST请求,基本语法如下:
1 | POST /_bulk |
其中:
index代表新增操作
- _index:指定索引库名
- _id指定要操作的文档id
- { “field1” : “value1” }:则是要新增的文档内容
delete代表删除操作
- _index:指定索引库名
- _id指定要操作的文档id
update代表更新操作
- _index:指定索引库名
- _id指定要操作的文档id
- { “doc” : {“field2” : “value2”} }:要更新的文档字段
示例,批量新增:
1 | POST /_bulk |
批量删除:
1 | POST /_bulk |
四、DSL查询
4.1、总体概述
DSL查询是一种基于 JSON 的查询语言,用于构建复杂的搜索请求。DSL 提供了丰富的查询和过滤功能,可以精确地控制搜索行为。DSL 查询主要分为两种类型:叶子查询(Leaf Query Clauses)和复合查询(Compound Query Clauses)
—–摘自百度百科嗷!
4.2、查询的基本结构
1 | GET /索引名/_search |
例如查询某个索引中的全部文档
1 | GET /items/_search |
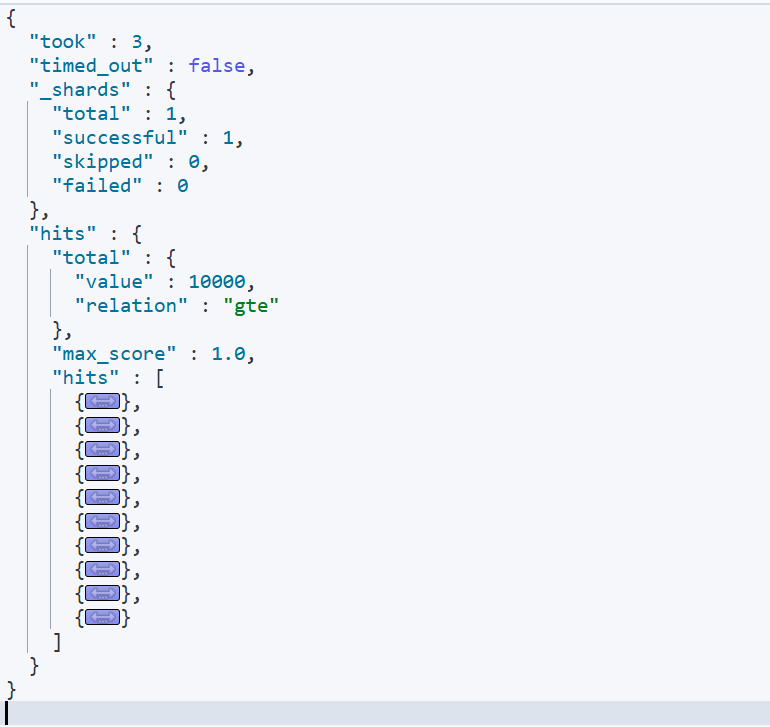
贴一下一次查询的结果,单次允许最多10000条数据,默认返回给你10条,数据就不看了哈,就是mapping映射的哪些数据。
4.3、叶子查询
4.3.1、全文检索:利用分词器对用户输入的内容分词,然后去词条列表中匹配,拿到文档id
1 | GET /my_index/_search // 1. 请求路径 /_search是固定的 |
match只能查一个字段,而multi_match可以查多个字段。把match换成multi_match,query内容不变,再下面多加一个”fileds”:[“字段1”,”字段2”….],有哪些字段涉及到你要查询的内容,这个里面就有多少个字段。
4.3.2、精确查询-term
1 | GET /products/_search |
4.4、复合查询
4.4.1、bool查询:基于逻辑运算组合叶子查询,实现组合条件。
must=“与”、should=“或”、must_not=“非”、filter=“过滤”。
1 | GET /shop/_search //去名为 shop 的索引里做一次搜索。 |
总体意思就是:到 shop 索引里,把所有 标题里有 iPhone 且 状态为 on_sale、价格≤8999、品牌不是山寨 的商品找出来;在这些结果里,如果商品还贴了 5G 或 NFC 标签,就把它们的分数据高,但至少得贴其中一种标签才合格。
must 和 should 同时存在时,如果 minimum_should_match 不写,should 变成“可选”,结果不符合预期。

感觉这种商城里面的搜索商品会常常用到bool查询 ,搜索关键字用到must,下面的筛选用fillter,不参与算分
4.4.2、dis_max——最佳字段搜索
场景:多字段查询,只要“一个字段最匹配”就算赢,避免把分数平均拉低。
1 | GET /book/_search 去 book 索引里搜一次。 |
tips:tie_breaker=0 时,完全取最高分;设 0.1~0.3 可以让次相关字段稍微贡献点分数,更柔和。
这个查询的意思就是:到 book 索引里,找那些在 title 或 abs 里提到 Java 的书;只看两者中更匹配的那一侧打分,再把另一侧分数的 30% 当‘安慰奖’加进来,最终按这个综合分排序返回
4.4.3、boosting——降低分数
出现场景:想让某些文档出现,但排到后面去;或者反之。
1 | GET /news/_search //在 news 索引里做一次查询 |
“boosting = 保留但降分,区别于 must_not 的直接踢掉。”
4.4.4、constant_score——固定加点分数
出现场景:只想用 filter,但又不想分数全部 0。filter过滤是不会算分数的。。。这个是不是有点鸡肋了?
1 | GET /video/_search |
结果所有匹配文档得分 = 1.2,简单粗暴。
简单说就是:到 video 索引里,把 is_vip=false 的所有纪录片(或任何视频)一次性捞出来;不管它们原来该得多少分,统一给 1.2 分,然后按这个固定分数返回。
使用场景
- 排行榜里“先按时间倒排,再细筛非 VIP”,需要保证所有非 VIP 分数相同。
- 还有。。。。。还有啥?
4.4.5、function_score——自定义函数算分
出现场景:销量、距离、热度、随机排序,全靠它。
1 | GET /hotel/_search |
先把所有名字里带『7天』的酒店搜出来,再用『离我当前位置(人民广场 31.2, 121.5)越近分越高』的高斯衰减函数把原分数加权,最终把距离因素和文本相关度乘在一起,离我 2 km 以内的酒店会排在最前面
核心能力:在基础查询得分 **_score** 上叠加自定义函数
生成新得分:新分数 = 原始分数 * 函数1 * 函数2 * …
函数1️⃣:weight权重函数,直接给文档加权
1 | { |
比如你收了💴,在用户搜索时,把他家的商品的分数提高2倍。充值了
1 | GET /coffee/_search |
函数2️⃣:field_value_factor 字段值函数,用字段值动态影响得分
4.5、聚合-Aggregation
聚合(Aggregation)是 ES 提供的“内置数据透视表”:在已筛选的文档上,先做 桶(分组)、再做 指标(统计)、最后可选 管道(二次运算),最终把大数据变成可读的指标、图表或报表
当你在电商平台搜索“咖啡”,左侧出现的:
- 品牌分布(雀巢 32件)
- 价格区间(50-100元 30件)yi
- 平均评分(4.6分)
这些数字不是原始文档,而是聚合(Aggregation) 对数据的统计结果
聚合本质:在查询结果上做统计分析(≠查询本身)三步走:
- Query:筛选目标文档(
**"query": { ... }**) - Bucket:文档分组装箱 → 生成桶
- Metric:桶内数值计算 → 生成指标
- Pipeline(可选):指标二次加工 → 高级分析
- Query:筛选目标文档(
核心口诀:先桶(Bucket) → 再指标(Metric) → 可选管道(Pipeline)
1 | Bucket(桶)——把文档分组 |
一些例子:
1、销量排行榜(桶+指标)
1 | GET /coffee/_search |
size=0:聚合时跳过文档返回
意思就是:把 coffee 索引里所有文档按brands字段分组,再对每个组的sales字段进行求和。最后然回统计的数据,有多少品牌,每个品牌的销量是多少。
返回的结果类似于:
1 | "brands": { |
2、价格区间统计(range)
1 | "aggs": { //aggs===aggregations |
意思就是:按价格把商品切成三段,返回每段有多少件、平均评分多少分
返回结果大概就这样:
1 | "price_ranges": { // 我们自定义的聚合名 |
3、每个月的订单量 (date_histogram)
1 | "aggs": { //开始聚合 |
一句话总结:把全部订单按下单日期切成“每月一桶”,返回每个月的订单数量,桶名用 2025-01、2025-02 … 这样的格式。
预期返回结果如下:
1 | "monthly_orders": { |
4、嵌套对象聚合(nested)假设每条商品有多个 skus(嵌套对象),想统计各 sku 的销量:
1 | "aggs": { //开始聚合 |
意思就是:把每条商品里的 嵌套 SKU 拎出来,按 颜色分组,输出每个颜色对应的 总库存量(qty 之和)
返回的结构大致如下:
1 | { |
5、月度增长率-管道聚合
1 | "aggs": { |
简单来说:把查询出来的数据,先桶分组,得到的结果给monthly_sales,分组的内容就是:根据字段date,以月为单位之间来分 桶,然后对每个桶里面的数据的字段amount进行求和,在这之后,按照按照月为单位,你应该得到了12个桶,每个桶里只有一条指标:sales = 当月销售额。接着用 derivative(一阶导数)对这 12 个 sales 值做一次【相邻差值】计算,就能拿到月环比增长率,结果放在 growth 里。
预期结果
1 | "aggregations": { |
数据聚合 = 先把大杂烩按规则装桶,再对桶里算指标,最后还能让桶与桶做二次运算
筛 👉 桶 👉 指标 👉 管
- 筛:query/filter
- 桶:terms / range / date_histogram
- 指:sum / avg / cardinality
- 管:derivative / cumulative_sum / bucket_script
(附官方文档:Elasticsearch Aggregations)
五、最后的总结
我们从倒排索引、mapping映射、索引结构、文档的CRUD到DSL查询和聚合,简单的梳理了一下elasticsearch的基本概念以及基本操作。
- Elasticsearch 的底层支撑是倒排索引:
按“词项 → 文档”的方式组织数据,实现全文搜索的高效性。 - 索引(Index)是数据容器,Mapping 定义数据结构:
字段类型、分词规则、是否创建倒排索引都由 Mapping 决定,设计阶段必须谨慎。 - Document 是最小的数据单元:
CRUD 操作支持全量更新、局部更新、批量写入,了解PUTvsPOST区别可以避免误用。 - DSL 查询与聚合是使用 ES 的核心:
通过match,term,bool等组合查询,以及terms,date_histogram,avg等聚合,满足搜索和统计需求。
既然这里提到了PUT和POST那就直接说一下吧,PUTVSPOST你们知道吗?
新增&更新 可以使用PUT和 POST,虽然都是写数据,但是差异明显
1、在新增数据的时候是否需要指定 _id
PUT必须指定_id用来明确主键,会更新或覆盖
POST可以省略_id,因为POST不是幂等操作,不指定id,es会自动生成一个唯一id
2、幂等性
PUT:幂等,多次相同请求不会重复创建,适合更新或覆盖。
POST:
- 不带
_id:永远新增,每次都会生成新文档(非幂等)。 - 带
_id:尝试新增,若_id已存在会抛version_conflict_engine_exception,并不会自动覆盖。
- 不带
幂等性(Idempotence) 是数学和计算机科学中的一个重要概念,指对同一操作进行多次重复执行所产生的结果与一次执行的结果相同。换句话说,无论操作执行1次还是N次,系统的最终状态保持一致。
😀这样就先完结了,后面还有什么要说的我在更新😀